大模型浪潮对 Java 生态系统的颠覆性影响:从计算核心到企业级 AI 业务编排者
过去几年,大语言模型(LLM)突然火到不行。ChatGPT、Claude、DeepSeek 一路狂奔,企业 IT 整体都被“推着”往 AI 时代走。对于 Java 开发者来说,大模型(LLM)的兴起似乎带来了挑战:模型训练和大规模推理主要由 Python 生态和专用硬件主导,前端全栈的兴起也给传统的 Java 开发带来了巨大的冲击。但是 Java 开发者真的要被时代抛在后面吗? 其实恰恰相反。 很多人只看到了“模型训练是 Python 的主场”,却忽略了一个更关键的事实:
绝大多数企业,并不会自己训练模型。企业最需要的,是把 AI 稳定、安全、高效地接入到已有的业务系统中。
而这一块,正是 Java 的强势领域。 企业里的业务系统——订单处理、供应链管理、CRM、财务、人事系统——90% 都是 Java 写的。 也就是说,当 AI 要真正“落地”时,它最终要进入的是:
- Java 的服务端
- Java 的中台
- Java 的微服务架构
- Java 维护的核心系统
这就导致一个新的现实:
Python 是 AI 时代的“模型生产线”,而 Java 仍然是企业的“业务基建”。
二者不是替代关系,而是“你做模型,我来让它落地”。 更重要的是: 随着企业对 AI 的使用越来越多,系统不再只是调一个模型,而是:
- 同时调用多个不同模型;
- 需要在高并发场景下调用模型;
- 需要确保模型输出的结果可控、格式正确;
- 需要处理超时、限流、失败重试等真正的工程问题;
- 需要保证业务级别的可靠性和一致性。
这些都是 Java 擅长、并且企业最信任的能力。 换句话说,随着 LLM 的普及,Java 开发的价值不仅没有下降,反而迎来了新的定位: 从“写业务代码的人”,变成了“让 AI 真正能在企业里跑起来的人”。
Java 的 AI 编排层——新一代框架与能力体系
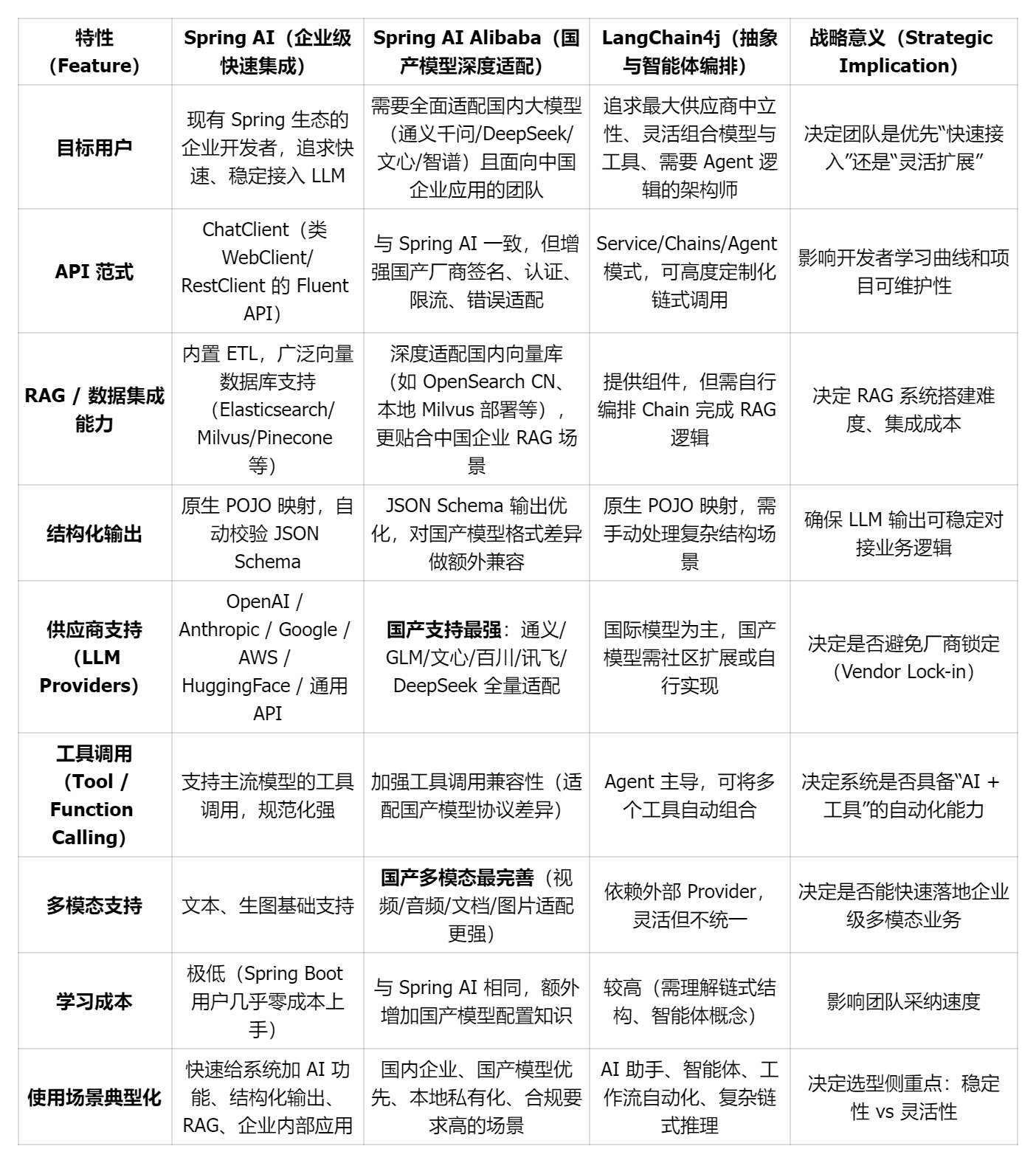
随着大模型在企业中的全面落地,Java 生态也迎来了加速演进。传统的 Java 服务主要处理业务逻辑,而在 AI 时代,它们要承担新的任务:如何让企业中的各种 LLM 模型(本地的、云端的、第三方 API)稳定、安全、可控地服务于真实业务场景。 这催生了一批新的 Java AI 框架,它们的目标很明确: 让 Java 开发者“像写普通业务服务一样使用 AI”。 我们就来看看 Java 的三大核心 AI 编排框架:
- Spring AI(官方版)
- LangChain4j(链式编排 / 智能体生态)
- Spring AI Alibaba(国内场景、国产模型支持最强)
Spring AI:最符合 Java 企业开发习惯的 AI 框架
Spring AI 可以理解为:
“让 Java 调用大模型变得像写 RestClient/WebClient 一样自然” 的官方基础框架。
对于写惯了 Spring Boot 的 Java 程序员来说,Spring AI 的学习成本非常低,它的设计理念完全沿用了 Spring 生态的基因。
框架定位:让 LLM 成为企业服务的一部分,而不是外部黑盒
Spring AI 想解决的核心问题是:
- 如何把外部的 AI API(OpenAI、DeepSeek、Claude、Google 乃至本地模型)
- 和企业自身的数据、业务 API 组合成一个可控的业务流程? 它通过 Spring Boot Starter、自动装配(AutoConfiguration)、配置化模型切换,让 Java 工程师不需要关心模型内部原理,也能快速将 LLM 融入业务。
ChatClient:像调用 REST 服务一样调用 LLM
Spring AI 最亮眼的能力,就是它的 Fluent API 设计——和 Spring WebClient 的风格高度一致:
String reply = chatClient.prompt()
.user("帮我总结一下这个订单内容")
.call()
.content();
调用 OpenAI、DeepSeek、Claude、Qwen(阿里)、Gemini,都只是换一个配置文件:
spring.ai.openai.api-key=xxx
spring.ai.deepseek.api-key=xxx
spring.ai.dashscope.api-key=xxx # 通义千问
不用改一行代码。 这对企业来说意味着:
底层模型可以随时切换,不会被任何一家厂商锁死(Vendor Lock-in)。
强类型输出:让大模型说“人话”,Java 接“结构化”
企业里最怕的是:模型给你一段“不确定格式的文本”。 Spring AI 通过 Typed Output 支持,把 AI 输出直接映射为 Java 对象:
record OrderSummary(int count, double price) {}
OrderSummary result = chatClient.prompt()
.user("从文本中提取订单信息")
.call()
.entity(OrderSummary.class);
如果 AI 输出格式不对? 框架会自动校验并报错,减少业务事故。
Spring AI 帮 Java 做的最关键能力:把“模型输出的不确定性”变成“后端可用的确定数据”。
RAG 全链路支持,让 Java 也能轻松做企业级知识库
RAG(检索增强生成)是企业中最常见的 AI 应用场景: FAQ、文档问答、客服知识库、法律合同检索…… Spring AI 原生支持:
- 文档解析(PDF/Word/网页自动拆分)
- Embedding(自动生成向量)
- 多种向量库: Elasticsearch / Milvus / Neo4j / PostgreSQL(PGVector) / Pinecone … 简单来说:
以前做 RAG 要搭一堆开源组件,现在 Java 用 Spring AI 直接一步到位。
Spring AI Alibaba:最强国产大模型支持 + 更本地化的能力
Spring AI 阿里版(Spring AI Alibaba)可以理解为: 专为国内企业场景设计的 Spring AI 增强版。 它在 Spring AI 官方框架的基础上,加强了: 对国内模型的深度适配 包括但不限于:
- 通义千问(Qwen)
- 讯飞星火
- 百度文心一言
- 百川
- 智谱 GLM
- DeepSeek(API版)
- Moonshot、MiniCPM 以及第三方云模型厂商 相比起 Spring AI 官方“兼容但轻量”的支持,Spring AI Alibaba 做了更“企业级”的适配(限流、重试、响应适配、签名方案等)。
企业更常用的能力:多模态、工具调用、结构化输出强化
阿里版框架更像是“Spring AI 的企业增强包”,包括:
- 更强的 function/tool calling(工具调用)
- 更贴合国内真实业务的 JSON Schema 输出增强
- 对多模态模型(图像、音频、视频)封装更完善
- 对国产模型 API 的模型能力差异做自动适配 简单来说:
如果你做的是国内企业项目,那么 Spring AI Alibaba 会比官方版本更实用。
LangChain4j:更灵活、更智能体化的 AI 编排框架
Spring AI 偏“工程化”与“可控性”,而 LangChain4j 更偏“能力玩法”,尤其适合构建复杂的 AI 智能体、链式流程等。 你可以把 LangChain4j 理解成 Java 版的 LangChain:
- 更灵活
- 更抽象
- 更强调“链条式调用 + 工具组合 + 智能体自治”
抽象层设计:模型、向量库、提示词、工具都是可替换组件
LangChain4j 把 AI 应用的不同组件(模型、向量库、提示词、工具)都抽象成了可配置的组件。 这意味着:
- 你可以根据业务需求,切换不同的模型(如 OpenAI、DeepSeek、通义千问等)
- 向量库可以从 Elasticsearch 切换到 Milvus
- 提示词模板可以自定义,而不是固定死在代码里
- 工具(如数据库查询、API 调用等)可以根据业务场景动态添加 这使得 LangChain4j 非常灵活,能够满足不同企业的定制化需求。
提示模板、记忆、智能体……应有尽有
LangChain4j 内置:
- Prompt Templates(提示模板)
- Memory(对话记忆)
- Agents(智能体,自动决策下一步任务)
- Tools(模型可调用的工具函数) 例如定义一个智能体:
@AiService
public interface Assistant {
String answer(String question);
}
JVM 基础架构的全面升级 —— AI 时代 Java 性能的底层支撑
大模型不仅改变了应用层的开发方式,也对 Java 的底层运行时(JVM)提出了前所未有的要求。 特别是在“高并发调用外部 LLM API”这一场景中,Java 正面临三个新的性能挑战:
- 大量高延迟 I/O(调用外部 LLM API)
- 对轻量级部署和快速启动的需求(云原生服务)
- 把推理压力完全交给云,而 Java 稳定负责编排 幸运的是,JVM 的现代化项目正在快速补上这块短板。
你现在看到的 Project Loom、GraalVM、云原生 MLOps 与 Java SDK,正是 Java 进入 AI 时代的底层基础。
Project Loom:虚拟线程让 Java 轻松面对海量 LLM API 调用
外部 LLM API 调用(如 DeepSeek、Groq、OpenAI)有一个共同特点:
推理(模型运算)很快,但网络 I/O 往返很慢。
一次请求返回可能要 100ms~2s。 在传统 Java 线程模型里,这是一场灾难:
- 每一次 API 调用都会占用一个操作系统线程
- 数百个请求就足以压垮线程池
- 并发量提高 → CPU/内存迅速上涨 → 雪崩 而 Project Loom(虚拟线程)彻底改变了这一局面。
虚拟线程是什么?一句话解释:你可以随便创建成千上万个线程,但几乎不占系统资源。
虚拟线程不是 OS 线程,而是 JVM 自己管理的轻量线程。 你可以像平时一样写同步代码,但获得接近 Go 协程的超高并发能力。 这直接解决了: AI 时代最致命的 Java 性能瓶颈 —— I/O 阻塞造成的线程耗尽。 也意味着:
- Java 不再需要“异步”才能应对高并发
- Java 微服务可以极高并发地调用各种 LLM API
- Java 对 Python 异步生态(async/await)的并发差距被彻底抹平 这对于把 Java 当作“AI 调用调度中心”的企业非常关键。
GraalVM Native Image:让 Java 拥有 Go/Rust 级别的启动速度和资源占用
在云原生场景(Kubernetes、FaaS、Serverless)中,Java 一直存在两大劣势:
- 启动慢(JVM 冷启动成本高)
- 内存占用大(动辄几百 MB) 在 AI 时代,这两个问题变得更加突出:
- RAG 服务
- Embedding 服务
- 内容审核服务
- Prompt 预处理服务
- 模型调用代理服务 这些都是轻量、高频、可能需要弹性扩容的小服务。 GraalVM 的 Native Image 就是为此而生的。
Java 在 AI 时代的重生与使命
经历了过去十年的云原生浪潮,我们曾一度认为 Java 在新时代中的角色会逐渐固化:稳定、可靠,但不再前沿。
然而,大模型时代的到来却以一种出乎所有人意料的方式重新定义了 Java ——
不是作为模型训练的语言,而是作为 AI 落地企业级生产系统的核心力量。
- 从 Spring AI、LangChain4j 到 Spring AI Alibaba,Java 生态在不到两年的时间里迅速完成了对生成式 AI 的接轨;
- 从 Project Loom 到 GraalVM Native Image,JVM 在底层性能、并发能力、部署形态上的升级,使得 Java 再次站在了技术革新的最前沿;
- 从 RAG、Prompt 工程、向量数据库 到 模型供应商中立性,Java 用工程化和可靠性为企业构建了一条真正可控、可治理、可扩展的 AI 采用路径。
我们看到一个清晰的技术趋势正在形成:
Python 在生产模型,Java 在生产价值。
在企业环境中,真正决定 AI 是否能落地的,从来不是模型本身,而是:
- 如何与私有数据结合?
- 如何保证稳定、可控、可审计?
- 如何大规模调用模型而不被延迟拖垮?
- 如何在成本与性能之间找到平衡?
- 如何让 AI 能够作为业务的一部分长期运行?
这些问题,没有一种脚本语言可以独自解决。
但 Java 可以。
甚至可以说:
AI 在企业规模落地的未来,本质上是一场 JVM、云原生与生成式 AI 的深度融合。
而 Java —— 凭借其生态、工程化能力、类型安全、治理体系和全新的性能基础设施 —— 正在成为这场融合的关键力量。